Optimisation linťaire
Optimisation linťaire
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Ce cours d'optimisation linťaire est destinť ŗ des ťtudiants en Mathťmatiques apliquťes ou Informatique, niveau troisiŤme annťe universitaire. Il est basť essentiellement sur la rťfťrence ci-aprŤs :
:
Hťdi Nabli, ''Recherche Opťrationnelle : Algorithme du Simplexe et ses Applications'', Centre de Publication Universitaire, Tunisie (2006)
Ce livre propose entre autres
- une nouvelle mťthode de recherche d'une base rťalisable initiale pour l'algorithme du simplexe. Cette technique ne fait pas intervenir les variables artificielles. De plus il est souvent possible d'aboutir, en une seule itťration, ŗ une base rťalisable.
- Gr‚ce aux tableaux formels, une nouvelle alternative, autre que l'algorithme dual-simplexe, est proposťe.
- Pour les problŤmes de transport, un algorithme rťcursif pour la dťtermination des ťlťments d'un tableau de transport est mis en oeuvre.
Dans ce document, les rťsultats mathťmatiques sont donnťs sans dťmonstration. Pour plus de dťtails, on peut consulter la rťfťrence ci-dessus.
V Algorithme du simplexe standard
VI Dualitť en programmation linťaire
Vous trouverez ici une version pdf : docquadratic.pdf
Je remercie vivement Sophie Lemaire et Bernadette Perrin-Riou, enseignants-chercheurs ŗ l'universitť de Paris-Sud, pour leur aide prťcieuse ŗ rťaliser ce document interactif.
I Programmation linťaire
Optimisation linťaire
→ I Programmation linťaire
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Un programme linťaire est un problŤme dans lequel on est amenť ŗ maximiser (ou minimiser) une application linťaire, appelťe fonction d'objectif ou fonction ťconomique, sur un ensemble d'ťquations et/ou d'inťquations linťaires, dites contraintes. Autrement dit, la programmation linťaire est une branche des mathťmatiques qui a pour but de rťsoudre des problŤmes d'optimisation linťaire de type
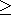 ''. En multipliant chaque inťgalitť de type ''
'' par
, on peut supposer que toutes les contraintes d'inťgalitť
sont de type ''
''. En multipliant chaque inťgalitť de type ''
'' par
, on peut supposer que toutes les contraintes d'inťgalitť
sont de type ''
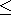 ''.
''.
Optimisation linťaire
→ I Programmation linťaire
I-1 Gťnťralitťs
Optimisation linťaire
→
I Programmation linťaire
→ I-1 Gťnťralitťs
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dans le contexte de la programmation linťaire, le terme programmation dťsigne l'organisation des calculs et non la rťalisation d'un programme informatique. Du point de vue des applications, l'optimisation linťaire est d'une grande portťe. Elle s'applique ŗ des problŤmes trŤs variťs qui sont issus de l'ťconomie, de l'ingťnierie, de la physique ou encore des modŤles probabilistes. Dans ce cadre, on peut citer par exemple, les problŤmes de type gestion de stock, gestion de production, transport de marchandise, affectation du personnel, systŤmes industriels, rťseaux de communication, etc. Pour les modŤles de programmation linťaire, on est souvent amenť ŗ maximiser un gain ou minimiser un coŻt. Ceci explique d'ailleurs pourquoi la fonction ŗ maximiser s'appelle fonction d'objectif ou ťconomique.
Optimisation linťaire
→
I Programmation linťaire
→ I-1 Gťnťralitťs
I-2 Exemple
Optimisation linťaire
→
I Programmation linťaire
→ I-2 Exemple
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Exemple
Une usine fabrique deux produits (A) et (B) ŗ
l'aide des matiŤres premiŤres I, II et III. Le fonctionnement
de l'usine est comme suit :
- unitť du produit (A) nťcessite unitťs de I et unitť de II.
- unitť du produit (B) nťcessite unitť de I, unitťs de II et unitť de III.
Formulation mathťmatique
Si on dťsigne respectivement par
et
les
quantitťs vendues du produit (A) et (B), le gain total vaut
D'autre part, la disponibilitť en matiŤres premiŤres revient
ŗ exiger des quantitťs, utilisťes pour la
fabrication de
et
, qui soient infťrieures aux
quantitťs disponibles. Ces contraintes s'expriment par les inťgalitťs
suivantes :
Bien entendu, les variables
et
doivent Ítre
positives. En conclusion, le problŤme de maximisation du profit
se traduit mathťmatiquement par un programme linťaire qui
s'ťcrit sous la forme :
Optimisation linťaire
→
I Programmation linťaire
→ I-2 Exemple
I-3 Domaine rťalisable
Optimisation linťaire
→
I Programmation linťaire
→ I-3 Domaine rťalisable
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Pour un problŤme d'optimisation linťaire, tout point qui vťrifie l'ensemble des contraintes s'appelle point rťalisable ou admissible. L'ensemble de tous les points rťalisables s'appelle domaine rťalisable. Il est facile de vťrifier que le domaine rťalisable d'un programme linťaire est convexe. On rappelle qu'un ensemble est dit convexe si ŗ chaque fois qu'il contient deux points et , il contient le segment joignant et . Ce segment est souvent notť par et il est dťfini par
Optimisation linťaire
→
I Programmation linťaire
→ I-3 Domaine rťalisable
I-4 Prťsentation des mťthodes
Optimisation linťaire
→
I Programmation linťaire
→ I-4 Prťsentation des mťthodes
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Nous allons prťsenter des techniques qui permettent de rťsoudre les programmes linťaires que l'on convient dťsormais de noter (PL). Diverses mťthodes ont ťtť proposťes dans la littťrature :
- La mťthode graphique : l'utilisation de cette mťthode est restreinte aux (PL) ayant un nombre de variables au plus ťgal ŗ .
- La mťthode des sommets : le nombre de sommets ťtant prohibitif, cette mťthode est trŤs coŻteuse en temps de calcul.
- La mťthode du simplexe : algorithme itťratif mis au point par George Dantzig en 1951.
Optimisation linťaire
→
I Programmation linťaire
→ I-4 Prťsentation des mťthodes
II Mťthode graphique
Optimisation linťaire
→ II Mťthode graphique
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Nous allons dťcrire la mťthode graphique ŗ travers trois exemples reprťsentatifs, ayant chacun deux variables structurelles. Le premier admet une et une seule solution optimale. Le deuxiŤme admet une infinitť de solutions optimales. Par contre, le troisiŤme exemple n'admet aucune solution optimale.
La rťsolution d'un (PL) par la mťthode graphique se fait selon une dťmarche commune, celle-ci peut Ítre rťsumťe en quatre directives :
- Schťmatiser le domaine rťalisable dans un repŤre orthonormť.
- Dans le mÍme repŤre, reprťsenter l'hyperplan . Noter que tout hyperplan d'ťquation , , est parallŤle ŗ .
- Si le (PL) considťrť est de type maximisation ( resp. minimisation), indiquer, par une flŤche, le sens de dťplacement parallŤle de qui fait augmenter ( resp. diminuer) .
- Dťterminer la droite la plus ťloignťe (dans le sens de la flŤche) de et qui coupe le domaine rťalisable . Tout point de est une solution optimale. Si une telle droite n'existe pas, cela veut dire que l'optimum est infini.
Optimisation linťaire
→ II Mťthode graphique
II-1 Exemple 1
Optimisation linťaire
→
II Mťthode graphique
→ II-1 Exemple 1
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Reprenons l'exemple
 |
| Reprťsentation graphique pour l'exemple 1 |
Le domaine rťalisable est schťmatisť en gris sur la Figure. Toute droite d'ťquation , oý est un rťel fixť, est parallŤle ŗ la droite : . On constate aussi que tout dťplacement parallŤle de dans le sens de la flŤche (voir dessin ci-aprŤs) fait augmenter . Donc maximiser la fonction , tout en satisfaisant aux contraintes du problŤme, revient ŗ chercher la droite la plus ťloignťe (dans le sens de la flŤche) de et qui coupe le domaine rťalisable. Du point de vue graphique, il s'agit de la droite passant par le point et parallŤle ŗ . Ainsi, on peut conclure que le point est la seule solution optimale qui donne une valeur maximale de la fonction d'objectif ťgale ŗ . Autrement dit, le meilleur profit vaut DT obtenu en fabriquant unitťs du produit (A) et unitťs du produit (B).
Optimisation linťaire
→
II Mťthode graphique
→ II-1 Exemple 1
II-2 Exemple 2
Optimisation linťaire
→
II Mťthode graphique
→ II-2 Exemple 2
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On considŤre le (PL) suivant :
 |
| Reprťsentation graphique pour l'Exemple 2 |
Le domaine rťalisable est la partie non bornťe reprťsentťe partiellement en gris sur la Figure. Tout dťplacement parallŤle de dans le sens de la flŤche (voir dessin ci-aprŤs) fait augmenter . Donc tout point de la demi-droite est optimal et la valeur maximale de vaut (voir dessin ci-aprŤs).
Optimisation linťaire
→
II Mťthode graphique
→ II-2 Exemple 2
II-3 Exemple 3
Optimisation linťaire
→
II Mťthode graphique
→ II-3 Exemple 3
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On considŤre maintenant le (PL) suivant :
 |
| Reprťsentation graphique pour l'Exemple 3 |
Le domaine rťalisable associť ŗ ce (PL) est la partie non bornťe reprťsentťe partiellement en gris dans la Figure. Dans le graphique, on observe que toute droite d'ťquation , avec , coupe le domaine rťalisable. Donc, et par consťquent, le problŤme n'admet aucune solution optimale (voir dessin ci-dessous).
Optimisation linťaire
→
II Mťthode graphique
→ II-3 Exemple 3
II-4 Remarque
Optimisation linťaire
→
II Mťthode graphique
→ II-4 Remarque
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Tous les exemples traitťs ci-dessus possŤdent deux
variables structurelles
et
. Pour des (PL) en dimension
, le raisonnement pour la mťthode graphique reste le mÍme.
La seule diffťrence est que l'ensemble des points
vťrifiant une contrainte
se reprťsente par un demi-espace
qui est dťlimitť par le plan d'ťquation
Optimisation linťaire
→
II Mťthode graphique
→ II-4 Remarque
II-5 Exercice
Optimisation linťaire
→
II Mťthode graphique
→ II-5 Exercice
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Exercice
A venir
Optimisation linťaire
→
II Mťthode graphique
→ II-5 Exercice
III Mťthode des sommets
Optimisation linťaire
→ III Mťthode des sommets
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
La mťthode des sommetsest simple, elle se base sur la rťsolution des systŤmes linťaires de Cramer. Cependant, elle est dans la pratique inexploitable car le nombre de systŤmes ŗ rťsoudre est en gťnťral trop important.
Nťanmoins, la mťthode des sommets est d'une utilitť incontestable : la recherche de l'optimum ťventuel sur tout le domaine rťalisable se ramŤne au calcul de l'optimum de la fonction d'objectif restreinte ŗ un sous ensemble fini. Ce rťsultat sera l'un des outils clť de la mťthode du simplexe.
Dťfinition
Optimisation linťaire
→ III Mťthode des sommets
III-1 Rťsultat prťliminaire
Optimisation linťaire
→
III Mťthode des sommets
→ III-1 Rťsultat prťliminaire
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Considťrons un (PL) ŗ variables rťelles. Un point du domaine rťalisable est appelť sommet, s'il existe hyperplans frontiŤres dont l'intersection est rťduite ŗ .
ThťorŤme
Soit
une application linťaire et
un polyŤdre de
. Si
admet son optimum
global en un point de
, il est
aussi atteint en un sommet de
.
Sans nul doute, l'intťrÍt de ce thťorŤme est immťdiat :
L'optimum (que ce soit maximum ou minimum) d'un
(PL), lorsqu'il existe, peut toujours Ítre rťalisť sur un
sommet.
La mťthode des sommets pour la rťsolution d'un (PL), consiste donc ŗ :
- dťterminer tous les sommets du domaine rťalisable,
- puis calculer la valeur de en chacun de ces sommets.
Exercice
Application 1 : ProblŤme de trains
Exercice
Application 2 : Production optimale
Optimisation linťaire
→
III Mťthode des sommets
→ III-1 Rťsultat prťliminaire
III-2 Mise en oeuvre
Optimisation linťaire
→
III Mťthode des sommets
→ III-2 Mise en oeuvre
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Appliquons la mťthode des sommets aux trois exemples prťcťdents. Pour l'exemple , les sommets du domaine rťalisable sont les points (voir Figure )
Exercice
Mťthode graphique gťnťrale
Optimisation linťaire
→
III Mťthode des sommets
→ III-2 Mise en oeuvre
III-3 Champ d'application
Optimisation linťaire
→
III Mťthode des sommets
→ III-3 Champ d'application
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
La mťthode des sommets peut s'appliquer mÍme pour des (PL) ayant un nombre de variables structurelles strictement supťrieur ŗ . Afin de dťterminer un sommet, on choisit hyperplans ( ťtant le nombre de variables) parmi les contraintes du domaine rťalisable (y compris les contraintes de positivitť : ). On obtient ainsi un systŤme linťaire d'ordre que l'on rťsoud. Si ce systŤme admet une et une seule solution , on vťrifie si satisfait les contraintes restantes. Dans ce cas, est un sommet, sinon le choix considťrť de ces ťquations linťaires ne permet pas d'avoir un sommet et pour ce faire, on effectue un autre choix de hyperplans frontiŤres parmi les contraintes. Dans le but d'obtenir tous les sommets, il va falloir balayer tous les choix possibles dont le nombre est ťgal ŗ . Chaque choix qui aboutit ŗ un systŤme de Cramer dont la solution est rťalisable permet d'obtenir un sommet. Enfin, la solution du problŤme considťrť est obtenue en prenant l'optimum de la fonction d'objectif sur tous les sommets.
Remarque
Dans la pratique, la mťthode des sommets est en fait trŤs
coŻteuse en temps de calcul. D'une part, la dťtermination
d'un sommet exige la rťsolution d'un systŤme linťaire de
Cramer d'ordre
dont la solution doit satisfaire les
contraintes restantes. D'autre part, le nombre
est en
gťnťral trŤs important. A titre indicatif, on a
! Par ailleurs, cette mťthode n'est
applicable que lorsqu'on
est certain que le (PL) admet une solution optimale, ce
qui est a priori difficile ŗ vťrifier.
Exercice
Rťsolution par la mťthode des sommets : A venir
Optimisation linťaire
→
III Mťthode des sommets
→ III-3 Champ d'application
IV Mťthode du simplexe
Optimisation linťaire
→ IV Mťthode du simplexe
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dans ce chapitre, nous allons ťtudier une mťthode qui ťvite de parcourir tous les sommets. Plus prťcisťment, le passage d'un sommet ŗ un autre se fait en amťliorant la valeur de la fonction ŗ optimiser. De plus, elle fournit un test qui permet d'affirmer le cas ťchťant que le problŤme n'admette pas de solution. Nous verrons que les rťsultats concernant les problŤmes de type maximisation, comparťs ŗ ceux relatifs aux problŤmes de minimisation, sont trŤs similaires.
IV-3 Relation entre la frome canonique et standard
Optimisation linťaire
→ IV Mťthode du simplexe
IV-1 Forme canonique
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-1 Forme canonique
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On convient de dire qu'un vecteur est infťrieur ŗ un vecteur , et on ťcrit , si pour tout , on a . Ici, le terme dťsigne la -iŤme composante du vecteur . Nous mettons en garde sur le fait que
la nťgation de n'est pas .
En effet, l'inťgalitť traduit la propriťtť pour toute composante . Par contre, la nťgation de , que l'on convient de noter , exprime que l'inťgalitť ait lieu pour au moins une composante .
Dťfinition
Une forme canonique ( resp.
forme standard)
est un (PL) oý toutes les
contraintes sont des inťgalitťs ( resp. ťgalitťs) et les variables
sont astreintes ŗ Ítre positives.
On a dťjŗ expliquť qu'on peut supposer et sans perte de gťnťralitť, que les contraintes d'inťgalitť sont toutes de type ''
''. Par
consťquent, on peut affirmer que tout (PL) sous forme canonique
s'ťcrit sous la forme suivante :
Le vecteur a composantes rťelles et dťsigne l'opťrateur transposť. Les inťgalitťs
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-1 Forme canonique
IV-2 Forme standard
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-2 Forme standard
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
La mise sous forme standard d'un (PL) quelconque consiste ŗ transformer les contraintes d'inťgalitťs (mise ŗ part les contraintes de positivitť) en ťgalitť tout en imposant aux variables d'Ítre positives. Pour ce faire, on procŤde comme suit :
- A chaque contrainte de type ''
'' (resp. ''
''),
ajouter (resp. retrancher) une variable tout en lui imposant
d'Ítre positive. Celle-ci s'appelle variable d'ťcart.
- Remplacer chaque variable sans restriction de signe par la diffťrence de deux variables positives : avec et .
- Si une variable est nťgative, effectuer le changement de variable .
Soit la forme canonique (FC) suivante :
max
sous les contraintes
0,
0
sous les contraintes
0,
0
Les donnťes de la forme standard de cette (FC) sont :
,
=
=
Exemple
On peut dire ŗ juste titre que ce (PL) n'est pas une forme canonique car la premiŤre contrainte est une ťgalitť et la troisiŤme variable n'est pas astreinte ŗ Ítre positive. Pour la mise sous forme standard, la premiŤre contrainte, qui est dťjŗ une ťgalitť, reste inchangťe. Pour la deuxiŤme, on lui retranche une variable positive , elle devient
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-2 Forme standard
IV-3 Relation entre la frome canonique et standard
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-3 Relation entre la frome canonique et standard
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
L'ťcriture d'un (PL) sous forme standard est introduite tout simplement parce que l'algorithme du simplexe ne s'applique qu'aux formes standards. En d'autres termes,
pour rťsoudre un (PL) par le simplexe, il faut tout d'abord l'ťcrire sous forme standard.
Etant donnť qu'on rťsoud le (PL) proprement dit et non la forme standard associťe, la question naturelle qu'on se pose est de savoir comment retrouver une solution optimale du (PL) de dťpart ŗ partir d'une solution optimale de sa forme standard. Le thťorŤme suivant ťtablit le lien entre une solution optimale d'un (PL) et celle de sa forme standard, et on se limite au cas oý le (PL) considťrť est une (FC).
ThťorŤme
est une solution optimale de (FC) si et seulement si
est une solution optimale de la forme
standard associťe. De plus, on a
Ce thťorŤme se gťnťralise bien ťvidemment pour tout (PL) quelque soit son type d'ťcriture. A titre d'illustration, pour l'Exemple qui n'est pas sous forme canonique, si est une solution optimale de la forme standard associťe, compte tenu des variables d'ťcarts et du changement de variable considťrťs, on peut dire que est une solution optimale du (PL) initial.
Exercice
Forme standard : ŗ venir
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-3 Relation entre la frome canonique et standard
IV-4 Notion de base rťalisable
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-4 Notion de base rťalisable
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dťsormais, on note tout (PL) ťcrit sous forme standard par (FS). Par dťfinition, l'ťcriture matricielle d'un problŤme (FS) possŤde la forme suivante :
sont fixťs.
La matrice
contient toujours plus de colonnes que de lignes
(i.e.
) vu que le nombre de variables
structurelles
(variables de dťcision + variables d'ťcarts
+ variables dŻes aux variables sans restriction
de signe) dťpasse le nombre de contraintes
. Sans perte de
gťnťralitť, on suppose que la matrice
est de rang
. Sinon,
- ou bien il y a une (ou plusieurs) ťquation qui est combinaison linťaire des autres ťquations, qu'il faut alors enlever,
- ou bien le systŤme est incompatible et dans ce cas le systŤme linťaire n'admet aucune solution.
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-4 Notion de base rťalisable
IV-4-1 SystŤme de base
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-1 SystŤme de base
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Notons par la colonne de . Le vecteur colonne s'ťcrit alors
une base du problŤme (FS) n'est autre qu'une sous matrice carrťe de d'ordre et inversible.
Pour mieux visualiser une telle base , on effectue des permutations de colonnes de sorte que la base apparaisse sur les premiŤres colonnes de . Ainsi, on met sous la forme suivante :
Les variables , , peuvent aussi Ítre classťes selon et :
Noter que toute solution de base rťalisable admet composantes nulles relatives aux variables hors base et que les autres composantes vťrifient un systŤme de Cramer d'ordre .
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-1 SystŤme de base
IV-4-2 Optimalitť et base rťalisable
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-2 Optimalitť et base rťalisable
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Par analogie au ThťorŤme , nous allons ťtablir que lorsque (FS) admet une solution, on peut toujours chercher une solution optimale parmi les solutions de base rťalisable.
ThťorŤme
Si un problŤme (FS) admet un optimum global, il existe toujours une
solution optimale qui est une solution de base rťalisable.
Remarque
Tout sommet du
domaine rťalisable
est une
solution de base rťalisable, la rťciproque est ťgalement vraie. Les sommets
de
correspondent donc aux solutions de base rťalisable. De
ce fait, l'algorithme du simplexe ne s'intťresse qu'aux solutions
de type
avec
. Ces solutions de base rťalisable sont bien ťvidemment en nombre fini.
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-2 Optimalitť et base rťalisable
IV-4-3 Base dťgťnťrťe
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-3 Base dťgťnťrťe
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Une solution de base rťalisable est dite dťgťnťrťe, si en plus des composantes nulles relatives ŗ , il existe une composante du vecteur qui est nulle. Elle est non dťgťnťrťe dans le cas oý toutes les composantes de sont non nulles et par suite strictement positives. De mÍme, on dit qu'une base rťalisable est dťgťnťrťe si la solution de base associťe est dťgťnťrťe. Il est intťressant de noter qu'un point dťgťnťrť est solution de plusieurs bases rťalisables. En effet, tout vecteur colonne relatif ŗ une base dťgťnťrťe admet au moins une coordonnťe , , qui est nulle. En considťrant que , on obtient
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-4 Notion de base rťalisable
→ IV-4-3 Base dťgťnťrťe
IV-5 Algorithme du simplexe
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-5 Algorithme du simplexe
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
L'algorithme du simplexe est un procťdť itťratif qui progresse dans un sens ťvolutif : il passe d'une solution de base rťalisable non optimale ŗ une autre solution ayant une meilleure valeur d'objectif. De cette faÁon, on ťvite de parcourir toutes les solutions de base rťalisable dont le nombre est en gťnťral prohibitif. Pour vťrifier la non optimalitť d'une solution, un simple test sera effectuť. De plus, gr‚ce ŗ l'algorithme du simplexe, on sera capable de dťtecter, le cas ťchťant, que l'optimum est infini.
Optimisation linťaire
→
IV Mťthode du simplexe
→ IV-5 Algorithme du simplexe
IV-5-1 Condition d'optimalitť
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-1 Condition d'optimalitť
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
La fonction d'objectif est entiŤrement dťfinie par la donnťe du vecteur . A chaque base , on note et . D'une faÁon ťquivalente, le vecteur (resp. ) s'obtient ŗ partir de en prenant les coordonnťe relatives aux variables de base (resp. hors base) associťe ŗ la matrice (resp. ). Le classement du vecteur selon et donne . Naturellement, on dit qu'une base est optimale si la solution associťe est optimale.
ThťorŤme
On se donne une base rťalisable
du problŤme (FS). Si la
forme standard (FS) est de type maximisation (resp.
minimisation), on considŤre le vecteur ligne
(resp.
). Alors, on a :
- (i) est optimale.
- (ii) Si de plus la base est non dťgťnťrťe (i.e. ), alors
La condition d'optimalitť peut Ítre interprťtťe comme un test d'arrÍt des itťrations pour l'algorithme du simplexe. Il reste ŗ dťcrire la technique qui permet de passer d'une solution de base rťalisable non optimale ŗ une autre solution de base rťalisable ayant une meilleure valeur ťconomique. Cette partie fera l'objet du paragraphe suivant.
Interprťtation
Donner une interprťtation ťconomique du
vecteur
. A partir de la solution rťalisable
, on construit le point
obtenu en augmentant d'une unitť la
-iŤme variable
hors base. D'aprŤs l'ťgalitť
BNyN
, ce point vaut
, oý
dťsigne le
-iŤme vecteur de la base canonique de
. Si
le point ainsi obtenu est rťalisable, on obtient :
Pour un problŤme de type maximisation, cette derniŤre
ťgalitť s'ťcrit
. Donc, l'ťlťment
reprťsente la quantitť s'ajoutant ŗ
la valeur ťconomique
lorsqu'on incrťmente d'une unitť
la
coordonnťe hors base de
, pour autant que le
nouveau point obtenu soit rťalisable. Semblablement, lorsqu'il s'agit d'un
problŤme de minimisation,
correspond ŗ la valeur retranchťe de la
valeur ťconomique. C'est la raison pour
laquelle
s'appelle vecteur des coŻts rťduits (ou
coŻts fictifs ou encore coŻts marginaux).
Exercice
Sommet-Base-Optimalitť : A venir
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-1 Condition d'optimalitť
IV-5-2 Amťlioration de la fonction d'objectif
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-2 Amťlioration de la fonction d'objectif
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On se donne une base rťalisable . Le vecteur dťsigne la colonne de qui est ŗ fortiori une colonne de . On note aussi la colonne d'indice de la matrice . D'ailleurs, n'est autre oý est le -iŤme vecteur de la base canonique de .
ThťorŤme
On suppose que la base rťalisable
vťrifie
. Il existe donc une composante
du
vecteur
qui est strictement positive. Considťrons le
vecteur colonne
de la matrice
. Alors de deux choses l'une
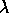 est
atteint (i.e.
). Alors,
la matrice
, obtenue ŗ partir de
en remplaÁant le vecteur colonne
par
, est une base rťalisable. La solution de base
associťe ŗ
vťrifie
De plus, on a
, selon que
(FS) soit de tupe maximisation ou minilisation. Ici, le point
reprťsente la solution de base rťalisable associťe
ŗ
:
.
est
atteint (i.e.
). Alors,
la matrice
, obtenue ŗ partir de
en remplaÁant le vecteur colonne
par
, est une base rťalisable. La solution de base
associťe ŗ
vťrifie
De plus, on a
, selon que
(FS) soit de tupe maximisation ou minilisation. Ici, le point
reprťsente la solution de base rťalisable associťe
ŗ
:
.
- (i) ou bien , et dans ce cas l'optimum est infini,
- (ii) ou bien
. Dans ce cas, on
calcule le rťel
est
atteint (i.e.
). Alors,
la matrice
, obtenue ŗ partir de
en remplaÁant le vecteur colonne
par
, est une base rťalisable. La solution de base
associťe ŗ
vťrifie
Il est intťressant de remarquer que dans le cas oý la base rťalisable est non dťgťnťrťe, le paramŤtre
est strictement positif. Sans aucun doute, le point
construit
possŤde, en cas de non dťgťnťrescence,
une valeur ťconomique strictement meilleure que celle de
.
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-2 Amťlioration de la fonction d'objectif
IV-5-3 Algorithme
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
/* On suppose que l'on dispose d'une base rťalisable */
tant que faire
choisir telle que
si alors
optimum infini /* */
exit
sinon
calculer
dťterminer pour lequel
est atteint/* est remplacťe par */
/* est remplacťe par */
Calculer
Optimum atteint en et il vaut
/* Fin de l'algorithme */
IV-5-4 RŤgle de pivotage
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-4 RŤgle de pivotage
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dans la pratique, le choix de est souvent multiple, il se peut que plusieurs composantes soient strictement positives. Etant donnťe que la nouvelle solution vťrifie :
Il arrive aussi que le minimum
soit atteint pour deux ou plusieurs
coordonnťes diffťrentes. Dans ce cas de figure, on fixe
comme critŤre de choix pour l'indice
, la premiŤre
coordonnťe trouvťe
qui rťalise le minimum
.
Pour des raisons de stabilitť numťrique et par analogie avec
la mťthode de Gauss avec pivot partiel,
un autre critŤre de choix est souvent considťrť. Il consiste
ŗ choisir
de faÁon ŗ ce que
soit le plus ťlevť parmi les ťlťments
strictement positifs.
Le critŤre qui fixe le choix de
et de l'indice
s'appelle rŤgle de pivotage. La rŤgle qui prend systťmatique la plus grande valeur positive de
s'appelle
rŤgle du meilleur coŻt marginal, c'est cette rŤgle que l'on
adopte dans ce cours.
Optimisation linťaire
→
IV Mťthode du simplexe
→
IV-5 Algorithme du simplexe
→ IV-5-4 RŤgle de pivotage
V Algorithme du simplexe standard
Optimisation linťaire
→ V Algorithme du simplexe standard
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dans ce chapitre, les donnťes mise en oeuvre dans l'algorithme du simplexe seront reprťsentťes dans un tableau. A chaque itťration correspond un tableau appelť tableau simplexe. Des formules itťratives liant les ťlťments d'un tableau au tableau subsťquent seront ťgalement ťtablies.
Optimisation linťaire
→ V Algorithme du simplexe standard
V-1 Tableau simplexe
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-1 Tableau simplexe
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Les ťlťments qui interviennent dans l'algorithme du simplexe peuvent Ítre rťcapitulťs dans ce qui suit.
- Les variables de base et les variables hors base. La base rťalisable et la matrice seront immťdiatement identifiťes ŗ partir des variables de base et hors base.
- La solution associťe ŗ la base rťalisable . Puisque , on ne retient que le vecteur .
- Le vecteur pour tester l'optimalitť.
- La matrice
afin de calculer
et le
coefficient
.
- La valeur de la fonction
au point
qui est ťgale ŗ
 | ||
Les coordonnťes correspondent aux variables de base, et les coordonnťes correspondent aux variables hors base. Le terme dťsigne la valeur de la fonction d'objectif au point rťalisable . D'aprŤs l'indexation des variables de base, on a :
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-1 Tableau simplexe
V-2 Application
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-2 Application
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Comme application de l'algorithme du simplexe, nous allons rťsoudre les trois exemples du premier chapitre en utilisant les tableaux simplexe.
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-2 Application
V-2-1 Exemple 1
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Reprenons l'Exemple 1 :
-
On ťcrit ce probŤme sous forme standard.
En ajoutant les variables d'ťcart, on obtient :
-
On cherche un systŤme de variables de base rťalisable
Il est clair que forme un systŤme de variables de base rťalisable. La base associťe est , elle vťrifie bienPour cette base, on obtient :car etRappelons que les coordonnťes de chaque solution de base rťalisable sont classťes selon et . Pour la base , si on ťcrit les coordonnťes de la solution rťalisable dans l'ordre , , on obtient exactement le point .
-
Itťration 1
1
5
Le vecteur ligne n'est pas nťgatif, il contient deux composantes strictement positives. Il a ťtť convenu de choisir la plus grande qui est 5. Pour distinguer notre choix, on dťcide de l'ťcrire en gras. Faisant rťfťrence aux notations utilisťes dans le ThťorŤme , on a :Donc, au cours de l'itťration suivante, la variable hors base qui se situe au niveau de va devenir une variable de base. D'aprŤs le tableau ci-dessus, il s'agit de la variable . Pour dťterminer la variable qui prend place, il va falloir calculer le paramŤtre et en dťduire l'indice
.
D'aprŤs le mÍme tableau, on a :
et donc L'indice correspond alors ŗ la variable . On dťcide de mettre en gras l'ťlťment qui a permis de rťaliser le minimumEn rťsumť, lorsqu'on ťcrit en gras une composante de , cela signifie que la variable, figurant sur la mÍme colonne que du tableau simplexe, entre dans la base. Inversement, l'identification de permet de dťcider que la variable, situťe sur la mÍme ligne que sort de la base. Naturellement, ces deux variables s'appellent respectivement variable entrante et variable sortante.
-
Itťration 2
A ce stade de calcul, la base rťalisable est associťe aux variables . Pour la prochaine itťration, on aura besoin de ŗ la place de . Afin de ne pas encombrer le texte par les notations, il est naturel de garder les mÍmes symboles , et pour toutes les itťrations du
simplexe. En tenant compte de l'ordre des indices
des variables de base et de
, on obtient
Par un simple calcul, on vťrifie les ťgalitťs suivantes :Le tableau simplexe relatif ŗ cette itťration est
1 4
Noter que le vecteur peut Ítre calculť aussi via la formule

= =
De mÍme, la valeur qui correspond ŗ peut Ítre obtenue ŗ travers le rťsultat Ces deux constatations restent valables pour les itťrations qui suivent et pour n'importe quel exemple.
Pour ce tableau, le vecteur admet une seule composante strictement positive qui est . Donc, la variable entre dans la base au cours de l'itťration 3. En ce qui concerne le nouveau paramŤtre, on a :
Ainsi, la variable devient hors base. Il est intťressant de noter que les matrices et peuvent Ítre dťduites du tableau simplexe ŗ partir des variables de base et des variables hors base. Dans toute la suite et lors de l'exťcution d'une itťration simplexe, seul le tableau simplexe sera donnť. Bien entendu, on prťcisera en gras les ťlťments et et on calculera le coefficient, ŗ chaque fois que cela
s'avŤre nťcessaire.
-
Itťration 3
3 3 -
Itťration 4
- Conclusion
V-2-2 Exemple 2
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Pour l'Exemple 2, le (PL) considťrť est
-
On ťcrit ce probŤme sous forme standard.
En retranchant une variable d'ťcart ŗ la premiŤre contrainte, et en ajoutant une seconde ŗ la deuxiŤme, on obtient :
-
On cherche un systŤme de variables de base rťalisable
Prenons par exemple et montrons qu'il forme un systŤme de variables de base rťalisable. La matrice associťe ŗ ce systŤme vťrifie :Les composantes de ťtant positives, la matrice est une base rťalisable. On calculeetLa solution de base rťalisable relative ŗ est , elle donne une valeur d'objectif ťgale ŗ .
-
Itťration 1
412 -
Itťration 2
Le vecteur ligne ťtant nťgatif, la solution associťe est optimale pour (FS). Compte tenu du ThťorŤme , on peut affirmer que est une solution optimale de ce (PL) et que la valeur maximale de sur le domaine rťalisable est .
-
Remarque
On avait montrť ŗ l'aide du graphique que ce probŤme admettait une infinitť de solutions optimales. Ce rťsultat peut Ítre retrouvť via le dernier tableau simplexe. En effet, on remarque sur ce tableau une composante nulle. Le vecteur est ťgal ŗ , qui est nťgatif. Donc, tout point de la forme est rťalisable pour (FS) et ceci pour tout rťel positif. Du fait que
, la valeur de
, qui est ťgale ŗ
, reste inchangťe. Par suite, le point
est optimal pour (FS) quelque soit le rťel
positif
.
-
Conclusion
En ce qui concerne le (PL) associť, nous allons utiliser comme d'habitude le ThťorŤme . Si on classe les composantes de dans l'ordre , , on obtient . Par consťquent,est un point optimal pour (PL). Notons que est un vecteur directeur de la droite (voir Figure ). D'ailleurs, la demi-droite co''{5}ncide avec l'ensemble des points lorsque dťcrit
.
V-2-3 Exemple 3
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Pour l'Exemple 3 :
-
On ťcrit ce problŤme sous forme standard
On a :
-
On cherche un systŤme de variables de base rťalisable
Il est facile de vťrifier que est une base rťalisable.
-
Itťration 1
1
-
Conclusion
Pour ťcrit en gras, on a . Donc, d'aprŤs le ThťorŤme , le probŤme vťrifie :Plus prťcisťment, pour tout rťel , le point rťalisable possŤde une valeur d'objectif ťgale ŗ :dont la limite en vaut . Le point est ťgal ŗet par consťquent est un point rťalisable du (PL) initial et ceci pour tout rťel . Noter que dťcrit le demi axe lorsque parcourt l'ensemble des rťels positifs. D'aprŤs la
Figure
, tous ces points sont effectivement rťalisables.
V-3 Sommets et solutions de base
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-3 Sommets et solutions de base
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Tous les (PL) rťsolus jusqu'ici sont des formes canoniques puisque le domaine rťalisable de chacun peut s'ťcrire sous la forme
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-3 Sommets et solutions de base
V-4 Formules itťratives
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-4 Formules itťratives
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
A chaque itťration de l'algorithme du simplexe, on est contraint ŗ calculer la matrice et le vecteur ligne . Ces calculs exigent prťalablement la dťtermination de la matrice inverse . Dans cette section, nous allons voir comment surmonter cette difficultť. Tout simplement, on ťvitera le calcul de . Les ťlťments d'un tableau vont Ítre dťterminťs itťrativement ŗ partir des ťlťments du tableau prťcťdent.
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-4 Formules itťratives
V-4-1 Matrice du pivot
Optimisation linťaire
→
V Algorithme du simplexe standard
→
V-4 Formules itťratives
→ V-4-1 Matrice du pivot
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Posons la matrice rťelle rectangulaire avec . Aussi, on pose et oý (resp. ) dťsigne la colonne de (resp. ). Supposons qu'ŗ l'itťration relative ŗ la base , on ait permutť le vecteur colonne avec . Au niveau du tableau, cela revient ŗ ťcrire en gras l'ťlťment de la matrice
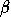 , que l'on
note communťment
. Par consťquent, au cours de la
prochaine itťration, on aura
, que l'on
note communťment
. Par consťquent, au cours de la
prochaine itťration, on aura
ThťorŤme
Afin de mieux visualiser les formules ťtablies dans le ThťorŤme , nous allons illustrer tout d'abord les ťlťments du tableau simplexe dans le schťma suivant. Le rťel { } correspond ŗ l'ťlťment ťcrit en gras au niveau de la matrice .
Ensuite, le tableau simplexe qui suit sera rempli moyennant des transformations qui peuvent Ítre rťsumťes en ces termes :
- au niveau de { }, on aura .
- Tout ťlťment de la colonne relative ŗ { } devient .
- Tout ťlťment de la ligne relative ŗ { } devient .
- Tout ťlťment en dehors de la ligne et de la colonne relative ŗ { } sera transformť en . Dans cette derniŤre expression, on tient ŗ prťciser que ( resp. ) est l'ťlťment de la matrice qui appartient ŗ la mÍme colonne (resp. ligne) que et la mÍme ligne (resp. colonne) que { }.
Optimisation linťaire
→
V Algorithme du simplexe standard
→
V-4 Formules itťratives
→ V-4-1 Matrice du pivot
V-4-2 Vecteur des coŻts rťduits
Optimisation linťaire
→
V Algorithme du simplexe standard
→
V-4 Formules itťratives
→ V-4-2 Vecteur des coŻts rťduits
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On garde ici le mÍme pivot . Cela veut dire que le vecteur colonne a ťtť ťchangť par et vice versa. Les formules ťtablies prťcťdemment pour vont conduire aux relations liant les composantes de avec celles de . Pour cela, on pose :
ThťorŤme
D'ores et dťjŗ, on peut observer que les relation liant ŗ sont les mÍmes que les relations entre une ligne et une ligne en dehors de la ligne du pivot . Le terme , qu'on a convenu d'ťcrire en gras, se situe sur la mÍme colonne du pivot. Il est remplacť par . Les opťrations qu'il faut appliquer sur , , en vue d'obtenir sont identiques ŗ celles effectuťes sur les termes de symbole dans le schťma du paragraphe prťcťdent.
Optimisation linťaire
→
V Algorithme du simplexe standard
→
V-4 Formules itťratives
→ V-4-2 Vecteur des coŻts rťduits
V-5 Algorithme du simplexe standard
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-5 Algorithme du simplexe standard
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
En ce qui concerne le vecteur , il a ťtť indiquť d'avance qu'il peut Ítre dťterminť par les relations
par sa valeur
, on obtient les mÍmes formules qui
rťgissent une colonne de
en dehors de la colonne du
pivot. Maintenant, l'ťlťment en bas ŗ droite du tableau simplexe, ŗ
savoir
, se calcule itťrativement via la relation
ou
selon que le probŤme
ťtudiť soit de type maximisation ou minimisation. En tenant
compte de l'expression de
, il est facile de constater que
la formule
s'identifie ŗ la formule
relative ŗ un ťlťment de symbole ''
''. Afin de garder les
mÍmes formules, il est souhaitable de remplacer
par
lorsqu'il s'agit d'un probŤme de type maximisation. Au niveau de
l'implťmentation sur machine, il est commode de dťfinir une
matrice, que l'on note
, qui contient les ťlťments
,
,
et
:
Algorithme du simplexe standard
Input: base rťalisable
Initialiser , et
Calculer
tant que faire
dťterminer l'indice pour lequel le maximum est atteint
si alors
optimum infini /* ou */
exit
sinon
calculer
dťterminer l'indice pour lequel
est atteintCalculer
Optimum vaut
Une solution optimale, que l'on note , est donnťe par :
Exercice
Rťsolution par les tableaux simplexe
Mťthode du simplexe
Mťthode du simplexe
Optimisation linťaire
→
V Algorithme du simplexe standard
→ V-5 Algorithme du simplexe standard
VI Dualitť en programmation linťaire
Optimisation linťaire
→ VI Dualitť en programmation linťaire
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Dans le cadre de la programmation linťaire, on peut associer ŗ chaque (PL) un autre (PL), de type opposť, nommť programme dual. Leurs propriťtťs sont ťtroitement liťes :
Par souci d'optimiser les calculs lors de la rťsolution d'un (PL), il est plus avantageux, dans certaines circonstances, de rťsoudre le probŤme dual. Ensuite, la solution du (PL) initial sera dťduite facilement par l'intermťdiaire de la solution du dual.
Une des consťquences les plus fructueuses de la notion de dualitť est l'algorithme dual-simplexe qui a ťtť conÁu, dans les annťes , par Lemke. Cet algorithme a un intťrÍt inťluctable en programmation linťaire.
Optimisation linťaire
→ VI Dualitť en programmation linťaire
VI-1 Primal - Dual
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→ VI-1 Primal - Dual
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→ VI-1 Primal - Dual
VI-1-1 Cas d'une forme canonique
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-1 Cas d'une forme canonique
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On considŤre un programme linťaire ťcrit sous forme canonique que l'on suppose de type maximisation :
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-1 Cas d'une forme canonique
VI-1-2 Cas gťnťral
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-2 Cas gťnťral
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
Tout programme linťaire ne s'ťcrit pas forcťment sous forme canonique. Il peut admettre en effet des contraintes d'ťgalitťs et/ou des variables sans restriction de signe (s.r.s. en abrťgť). De ce fait, la forme gťnťrale d'un primal de type maximisation s'ťcrit de la faÁon suivante :
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-2 Cas gťnťral
VI-1-3 Tableau rťcapitulatif
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-3 Tableau rťcapitulatif
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
On note que lorsque le primal est ťcrit sous une forme gťnťrale, son dual l'est aussi. Le tableau ci-dessous rťcapitule les rŤgles de correspondance entre un primal de type maximisation et son dual.
Primal | Dual |
| - Maximisation | - Minimisation |
| - Coefficients d'objectif | - Second membre |
| - Second membre | - Coefficients d'objectif |
| - Matrice rťgissant les contraintes | - Matrice transposťe |
- Relation liant les contraintes
| - Nature des variables
|
- Nature des variables
| - Relation liant les contraintes
|
Remarque
On aurait pu choisir comme primal un
probŤme de minimisation, le dual aurait ťtť alors un
programme linťaire de type maximisation. Tout simplement parce que le dual du dual
est le primal (facile ŗ prouver).
Autrement dit, si on permutait dans le tableau
prťcťdent les deux mots Primal et Dual, on obtiendrait les rŤgles
de correspondance entre un primal de minimisation et son dual.
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→
VI-1 Primal - Dual
→ VI-1-3 Tableau rťcapitulatif
VI-2 Optimalitť pour le primal-dual
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→ VI-2 Optimalitť pour le primal-dual
- I Programmation linťaire
- II Mťthode graphique
- III Mťthode des sommets
- IV Mťthode du simplexe
- V Algorithme du simplexe standard
- VI Dualitť en programmation linťaire
- Index
ThťorŤme
Si
et
sont deux solutions rťalisables de
et
respectivement, alors
.
Si de plus on a
, alors
et
sont
deux solutions optimales de
et
respectivement.
Dans la pratique, il est souvent difficile de trouver deux points rťalisables et de et tels que . La situation la plus envisageable consiste ŗ dťterminer une solution optimale du primal via par exemple le simplexe, puis essayer d'en dťgager une solution optimale du dual.
ThťorŤme
Soit
une base rťalisable de la forme standard
relative au primal
. Si la base
vťrifie
, alors
est une solution optimale du dual
.
Remarque
Afin de dťterminer la solution optimale
,
il est inutile de calculer la matrice inverse
. Il suffit, en effet, de rťsoudre le systŤme de
Cramer
. Par ailleurs, le ThťorŤme
prťcťdent n'exige aucune condition sur la nature du primal (
ou
).
Optimisation linťaire
→
VI Dualitť en programmation linťaire
→ VI-2 Optimalitť pour le primal-dual